728x90
-
HunyuanVideo를 ComfyUI에서 이미지에서 비디오로 생성하기
주요 요약- HunyuanVideo를 ComfyUI에서 이미지에서 비디오로 생성하려면 최신 버전의 ComfyUI를 설치하고 필요한 모델 파일을 다운로드해야 합니다.
- 모델 파일은 Hugging Face나 Civitai에서 다운로드 가능하며, 워크플로우는 ComfyUI 예제 페이지에서 가져올 수 있습니다.
- 이미지 입력과 텍스트 프롬프트를 조합하여 비디오를 생성하는 과정은 비교적 간단하지만, GPU 메모리와 설정에 따라 결과가 달라질 수 있습니다.
HunyuanVideo와 ComfyUI로 이미지에서 비디오 생성하기HunyuanVideo를 ComfyUI에서 사용하려면 먼저 최신 버전을 설치하세요. ComfyUI GitHub 저장소에서 다운로드할 수 있습니다. 일부 기능은 커스텀 노드가 필요할 수 있으니, 문제가 발생하면 kijai/ComfyUI-HunyanVideoWrapper에서 추가 노드를 설치하세요.다음 모델 파일을 다운로드하여 ComfyUI의 적절한 디렉토리에 배치하세요: 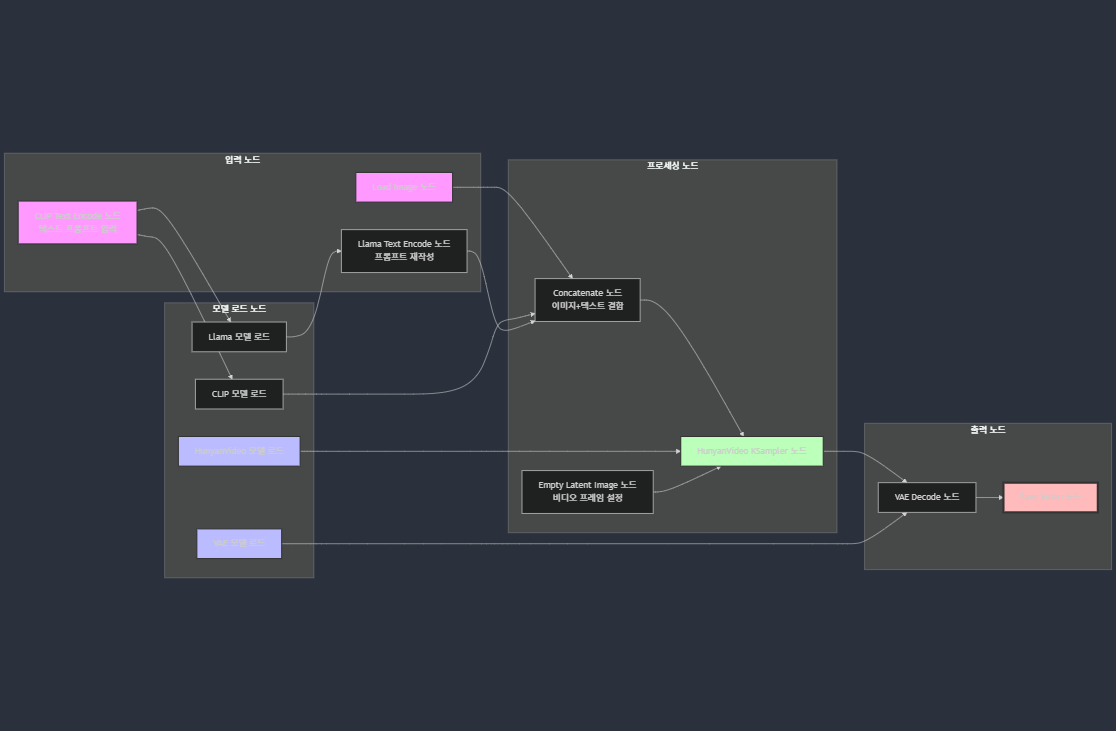
- 텍스트 인코더:
- clip_l.safetensors (openai/clip-vit-large_patch14)
- llava_llama3_fp8_scaled.safetensors (tencent/HunyanVideo-PromptRewrite)
- VAE:
- hunyan_video_vae_bf16.safetensors (Kijai/HunyanVideo_comfy)
- 디퓨전 모델:
- hunyan_video_t2v_720p_bf16.safetensors (Kijai/HunyanVideo_comfy)
- 워크플로우에서 빨간 블록이 나타나면 필요한 커스텀 노드가 설치되지 않은 것일 수 있습니다. "Manager" 탭에서 누락된 노드를 설치하고 ComfyUI를 재시작하세요.
- GPU 메모리가 부족할 경우 FP8 또는 FP32 버전의 모델을 사용하는 것을 고려하세요.
상세 보고서: HunyuanVideo와 ComfyUI로 이미지에서 비디오 생성하기배경 정보시스템 요구 사항- GPU 메모리: 720p 비디오의 경우 60GB, 544p 비디오의 경우 45GB, 80GB 이상 권장
- 운영 체제: Linux에서 테스트됨, CUDA 12.4 또는 11.8 필요
- ComfyUI 최신 버전
- 텍스트 인코더:
-
- 설치 후, 커스텀 노드가 필요할 수 있으니 문제가 발생하면 kijai/ComfyUI-HunyanVideoWrapper에서 추가 노드를 설치하세요.
- 커뮤니티 피드백에 따르면, 일부 사용자는 네이티브 지원으로도 충분히 작동하며, 커스텀 노드는 선택 사항입니다.
clip_l.safetensors openai/clip-vit-large_patch14 models/text_encoders/ llava_llama3_fp8_scaled.safetensors tencent/HunyanVideo-PromptRewrite models/text_encoders/ hunyan_video_vae_bf16.safetensors Kijai/HunyanVideo_comfy models/vae/ hunyan_video_t2v_720p_bf16.safetensors Kijai/HunyanVideo_comfy models/diffusion_models/ - 파일 크기는 상당히 크며, 예를 들어 hunyan_video_t2v_720p_bf16.safetensors는 약 25.6GB입니다. 충분한 저장 공간을 확보하세요.
- Hugging Face에서 다운로드 시 Git LFS를 지원하는 클라이언트를 사용하는 것이 좋습니다.
- ComfyUI/models/text_encoders/
- ComfyUI/models/vae/
- ComfyUI/models/diffusion_models/
-
- 워크플로우 JSON 파일 다운로드: ComfyUI 예제 페이지에서 "Image to Video" 섹션을 찾아 워크플로우 JSON 파일을 다운로드하세요. 이 파일은 이미 설정된 노드 연결을 포함하고 있습니다.
- 워크플로우 가져오기: ComfyUI 인터페이스에서 "Load" 버튼을 클릭하고 다운로드한 JSON 파일을 선택하세요.
- 입력 설정:
- 입력 이미지를 "Load Image" 노드에 연결하세요.
- 텍스트 프롬프트를 텍스트 인코더 노드에 입력하세요.
- 이미지와 텍스트를 결합하는 노드(예: Concatenate 또는 VLM 관련 노드)가 필요할 수 있습니다. 커뮤니티 피드백에 따르면, IP2V(Image-Prompt to Video) 워크플로우를 사용하는 것이 일반적입니다.
- 비디오 생성: "Queue" 버튼을 눌러 비디오 생성을 시작하세요. 생성 시간은 해상도와 프레임 수에 따라 달라질 수 있습니다.
- GPU 메모리 관리: VRAM이 부족할 경우, FP8 모델을 사용하거나 해상도를 낮추세요. 예를 들어, 8GB 카드에서는 320px 해상도로 설정하면 작동 가능합니다.
- 커스텀 노드 설치: 워크플로우에서 빨간 블록이 나타나면 "Manager" 탭에서 누락된 커스텀 노드를 설치하고 ComfyUI를 재시작하세요.
- 프롬프트 최적화: 텍스트 프롬프트는 비디오의 품질과 일관성에 큰 영향을 미칩니다. 예를 들어, "A panda riding a motorcycle in a busy New York City street, camera zooms out"와 같은 구체적인 프롬프트를 사용하는 것이 좋습니다.
- 성공적으로 설정하면, 입력 이미지를 기반으로 동적인 비디오를 생성할 수 있습니다. 예를 들어, 배경 이미지를 제공하고 "A person walking through the park"와 같은 프롬프트를 추가하면 해당 장면의 비디오가 생성됩니다.
- 한계로는 GPU 메모리 제한과 생성 품질의 변동성이 있습니다. 커뮤니티 피드백에 따르면, 낮은 해상도에서는 노이즈가 많을 수 있으니 설정을 조정하세요.
- 추가 도움은 ComfyUI 서브레딧에서 찾을 수 있습니다.
- HunyuanVideo 관련 최신 업데이트는 ComfyUI 블로그를 참고하세요.
- 문제 해결을 위해 Stable Diffusion Art 튜토리얼도 유용합니다.
주요 인용- ComfyUI GitHub 저장소에서 최신 릴리스 다운로드
- kijai/ComfyUI-HunyanVideoWrapper 커스텀 노드
- openai/clip-vit-large_patch14에서 clip_l.safetensors 다운로드
- tencent/HunyanVideo-PromptRewrite에서 llava_llama3_fp8_scaled.safetensors 다운로드
- Kijai/HunyanVideo_comfy에서 hunyan_video_vae_bf16.safetensors 다운로드
- Kijai/HunyanVideo_comfy에서 hunyan_video_t2v_720p_bf16.safetensors 다운로드
- ComfyUI 예제 페이지에서 워크플로우 확인
- 이 가이드를 따라가면 HunyuanVideo를 ComfyUI에서 효과적으로 사용하여 이미지에서 비디오를 생성할 수 있습니다. 모델 파일 다운로드와 워크플로우 설정은 약간의 시간이 걸릴 수 있지만, 한 번 설정하면 다양한 창작 활동에 활용할 수 있습니다. GPU 메모리와 설정에 따라 결과가 달라질 수 있으니, 실험을 통해 최적의 설정을 찾아보세요.
- 4. 워크플로우 설정: 이미지에서 비디오 생성
- 다운로드한 파일을 ComfyUI의 적절한 디렉토리에 배치하세요. 기본 디렉토리 구조는 다음과 같습니다:
- HunyuanVideo를 사용하려면 여러 모델 파일을 다운로드해야 합니다. 아래 표는 필요한 파일과 다운로드 소스를 정리한 것입니다:
- 1. ComfyUI 업데이트 및 준비
- HunyuanVideo를 실행하려면 다음과 같은 시스템 사양이 권장됩니다:
- HunyuanVideo는 Tencent에서 개발한 130억 개 파라미터를 가진 오픈소스 비디오 생성 모델로, 텍스트와 이미지 입력을 기반으로 고품질 비디오를 생성할 수 있습니다. ComfyUI는 Stable Diffusion 및 기타 AI 모델을 위한 사용자 친화적인 인터페이스로, HunyuanVideo의 네이티브 지원을 통해 이미지에서 비디오 생성이 가능합니다. 2024년 12월부터 ComfyUI에서 HunyuanVideo의 네이티브 지원이 발표되었으며, 2025년 3월 현재도 활발히 사용되고 있습니다.
- 이 보고서는 Tencent의 HunyuanVideo 모델을 ComfyUI에서 이미지에서 비디오로 생성하는 데 필요한 모든 단계를 상세히 설명합니다. 2025년 3월 9일 기준으로, 최신 정보와 커뮤니티 리소스를 기반으로 작성되었습니다. 이 가이드는 초보자부터 숙련된 사용자까지 쉽게 따라갈 수 있도록 설계되었으며, 필요한 다운로드 링크와 설정 방법을 포함합니다.
- 추가 팁
- 워크플로우 설정
- 모델 파일 다운로드 및 설치
- 준비 단계
728x90
'영상생성AI > ComfyUI' 카테고리의 다른 글
| [ComfyUI] LTX-Video 0.9.5 설정 및 사용 가이드 - 고품질 AI 비디오 생성하기 (1) | 2025.03.11 |
|---|---|
| LTX-Video: 텍스트와 이미지로 고품질 비디오 생성하기 (0) | 2025.03.11 |
| ComfyUI의 Flux: 간편한 이미지 생성 워크플로우 공유 기능 (0) | 2025.03.08 |
| ComfyUI-Zonos 사용 매뉴얼 (0) | 2025.03.07 |
| eSpeak-NG 릴리스 가이드 및 Zonos 연동 매뉴얼 (0) | 2025.03.07 |
![[ComfyUI] LTX-Video 0.9.5 설정 및 사용 가이드 - 고품질 AI 비디오 생성하기](http://i1.daumcdn.net/thumb/C176x120.fwebp.q85/?fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FtoDO4%2FbtsMF2jGzDN%2FAAAAAAAAAAAAAAAAAAAAANDis7-uAgTL6UUf5yeznfsAS_yLu6jndM18uMTvKf12%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3Di%252BWwg34lBusUumOvMuj882I4W1Y%253D)
