Whisper-WebUI: 자동 자막 생성 및 번역을 위한 완벽 가이드 (2025년 최신)
음성을 자동으로 텍스트화하고 자막을 생성하는 작업은 콘텐츠 제작자에게 필수적인 과정입니다. Whisper-WebUI는 OpenAI의 Whisper 모델을 웹 인터페이스로 쉽게 사용할 수 있게 해주는 강력한 도구입니다. 이 글에서는 Whisper-WebUI의 설치부터 고급 기능까지 상세히 알아보겠습니다.
📋 목차
Whisper-WebUI 개요
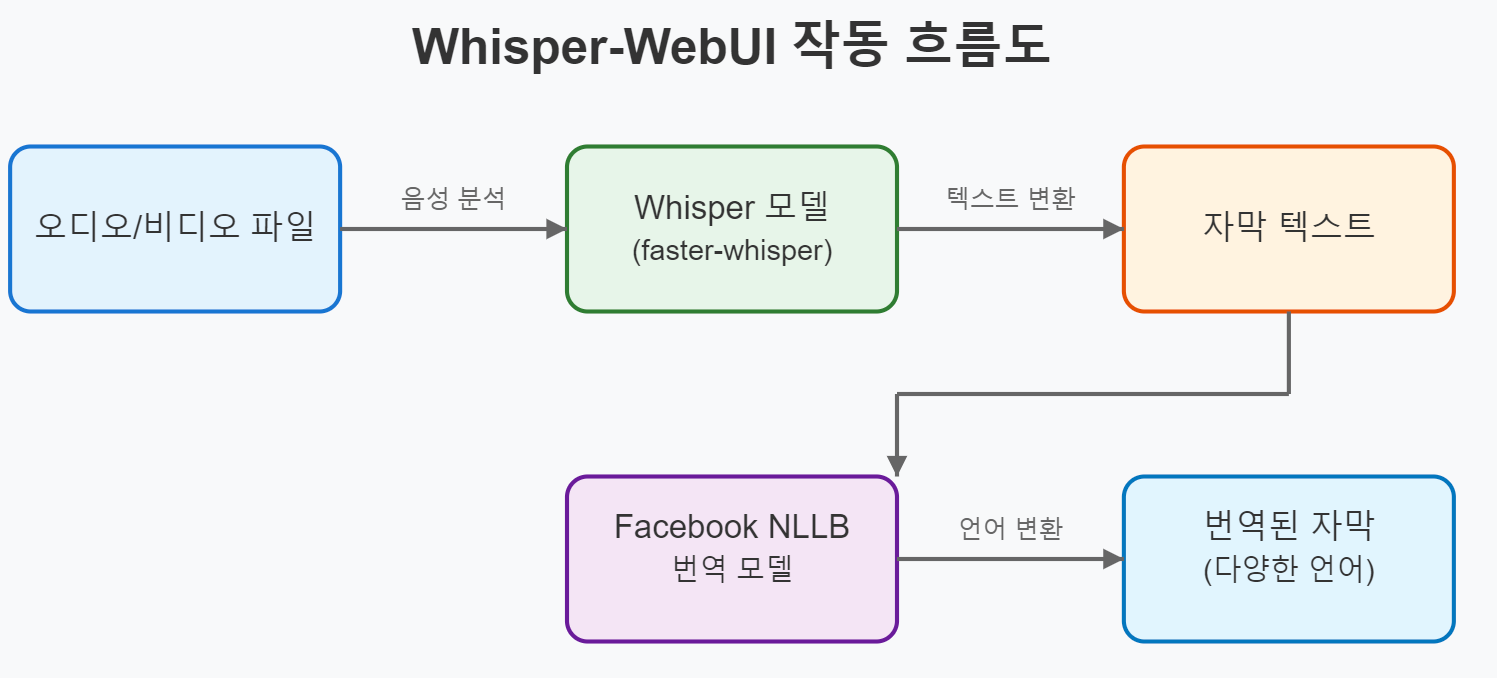
Whisper-WebUI는 OpenAI의 Whisper 음성 인식 모델을 기반으로 하는 웹 기반 사용자 인터페이스로, 주로 다음과 같은 목적으로 사용됩니다:
- 비디오/오디오 파일의 자동 자막 생성
- 생성된 자막의 번역 지원
- 효율적인 음성-텍스트(STT) 변환
이 도구는 Gradio를 사용해 브라우저 기반 인터페이스를 제공하며, 특히 콘텐츠 제작자와 번역가에게 유용합니다.
설치 가이드
전제 조건
Whisper-WebUI를 사용하기 위해서는 다음 소프트웨어가 필요합니다:
- Git: 저장소 복제용
- Python 3.10-3.12: 호환 가능한 Python 버전
- FFmpeg: 오디오/비디오 처리에 필수
설치 단계
# 1. GitHub에서 저장소 클론
git clone https://github.com/jhj0517/Whisper-WebUI.git
# 2. 프로젝트 디렉토리로 이동
cd Whisper-WebUI
# 3. 필요한 종속성 설치
pip install -r requirements.txt
💡 팁: 가상 환경(venv)을 사용하면 시스템 Python 환경과 충돌 없이 설치할 수 있습니다.
실행 방법
Whisper-WebUI는 다음 두 가지 방법으로 실행할 수 있습니다:
1. 스크립트 사용
- Windows: start-webui.bat 실행
- Linux/macOS: start-webui.sh 실행
2. 명령줄 인수 사용
python app.py --host 0.0.0.0 --port 7860
더 많은 명령줄 옵션은 GitHub 위키에서 확인할 수 있습니다.
주요 기능 및 장점
faster-whisper 모델 사용
Whisper-WebUI는 기본적으로 faster-whisper를 사용하여 처리 속도와 자원 효율성을 극대화합니다:
모델 GPU 메모리 CPU 메모리 처리 시간
| 원본 Whisper | 11,325MB | 9,439MB | 4분 30초 |
| faster-whisper | 4,755MB | 3,244MB | 54초 |
모델 다운로드 및 통합
- Hugging Face 저장소 ID를 입력하여 모델 자동 다운로드 지원
- 예: deepdml/faster-whisper-large-v3-turbo-ct2
- 사용자 정의 fine-tuned 모델을 models/Whisper/ 디렉토리에 배치 가능
자막 번역 기능
Whisper-WebUI는 Facebook NLLB 모델을 사용하여 다양한 언어로 자막을 번역할 수 있습니다. 이는 다국어 콘텐츠 제작자에게 특히 유용합니다.
자막 번역 설정
자막 번역 설정은 configs/translation.yaml 파일에서 관리할 수 있습니다. 기본적으로 다음과 같은 설정이 포함되어 있습니다:
# 번역 설정 예시
model: "facebook/nllb-200-distilled-600M" # 사용할 번역 모델
source_language: "eng_Latn" # 소스 언어 코드
target_language: "kor_Hang" # 목표 언어 코드 (한국어)
batch_size: 8 # 배치 처리 크기
💡 참고: 번역 품질을 높이려면 더 큰 모델(예: facebook/nllb-200-3.3B)을 사용하세요.
Docker 및 Colab 환경에서 실행
Docker 설정
Docker를 통해 Whisper-WebUI를 실행하려면:
- Docker Desktop 설치
- 다음 명령어 실행:
# docker-compose.yaml 파일이 있는 디렉토리에서
docker-compose up -d
Colab 노트북
Google Colab에서 Whisper-WebUI를 실행하려면:
- Colab 노트북 링크 접속
- 노트북 지시에 따라 실행
이 방법은 고사양 GPU가 없는 사용자에게 특히 유용합니다.
고급 사용법
명령줄 인수 옵션
다양한 명령줄 인수를 통해 Whisper-WebUI의 동작을 조정할 수 있습니다:
python app.py --whisper_type "faster" --whisper_model "large-v3" --server_name "0.0.0.0" --port 8080
주요 인수 목록:
- --whisper_type: 사용할 Whisper 구현체 (기본값: "faster")
- --whisper_model: 사용할 모델 크기 (기본값: "large-v2")
- --server_name: 호스트 주소 (기본값: "127.0.0.1")
- --port: 포트 번호 (기본값: 7860)
- --diarize: 화자 구분 기능 활성화 (기본값: False)
백엔드 REST API 활용
Whisper-WebUI는 REST API를 통해 프로그래밍 방식으로 접근할 수 있습니다. API 경로는 다음과 같습니다:
- /api/transcribe: 음성-텍스트 변환
- /api/translate: 자막 번역
- /api/models: 사용 가능한 모델 목록
FAQ
Q: 어떤 모델 크기를 선택해야 할까요?
A: 일반적으로 "large-v3"가 정확도와 속도의 균형이 좋습니다. 리소스가 제한적이라면 "medium" 또는 "small"을, 최고의 정확도를 원한다면 "large-v3"를 권장합니다.
Q: GPU 없이도 사용할 수 있나요?
A: 네, CPU에서도 실행 가능하지만 처리 속도가 느립니다. 긴 영상에는 GPU 사용을 권장합니다.
Q: 지원되는 입력 파일 형식은 무엇인가요?
A: MP4, MP3, WAV, M4A 등 FFmpeg가 지원하는 대부분의 오디오/비디오 형식이 지원됩니다.
Q: 한국어 인식 정확도는 어떤가요?
A: Whisper 모델은 한국어를 포함한 다양한 언어에서 높은 정확도를 보이지만, 방언이나 전문 용어가 많은 경우 정확도가 떨어질 수 있습니다.
최종 요약 및 앞으로의 개발 계획
Whisper-WebUI는 효율적인 자동 자막 생성 도구로, faster-whisper의 도입으로 처리 속도와 메모리 효율성이 크게 향상되었습니다. 다양한 실행 옵션(Docker, Colab)과 번역 기능은 사용자 경험을 더욱 향상시킵니다.
향후 개발 계획에는 다음과 같은 기능이 포함되어 있습니다:
- DeepL API 통합
- NLLB 모델 개선
- UVR(Ultimate Vocal Remover) 통합
- 실시간 전사 기능
'영상생성AI > 비디오 오디오 생성 Site' 카테고리의 다른 글
| ArtBot: AI로 생성된 예술을 위한 사용자 친화적인 인터페이스 (0) | 2025.05.22 |
|---|---|
| MIDI: 단일 이미지에서 3D 장면 생성하는 최첨단 기술 가이드 (2) | 2025.03.18 |
| Remade Effects: 이미지를 생동감 있는 비디오로 변환하는 AI 도구 완벽 가이드 (0) | 2025.03.18 |
| Captions.ai API 완벽 가이드: 비디오 생성부터 편집까지 모든 것 (1) | 2025.03.18 |
| CSM-1B: 대화형 음성 모델 설정 및 사용 완벽 가이드 (2025) (0) | 2025.03.18 |

