Wan 2.1에서 LoRA 사용하기: 맞춤형 AI 비디오 생성의 완벽 가이드

AI 비디오 생성 분야에서 혁신적인 모델로 주목받고 있는 Wan 2.1을 더욱 강력하게 활용할 수 있는 방법을 찾고 계신가요? LoRA(Low-Rank Adaptation)는 이 강력한 모델을 여러분만의 스타일과 효과로 맞춤화할 수 있는 핵심 도구입니다. 이 글에서는 Wan 2.1에서 LoRA를 사용하는 방법부터 자체 LoRA 모델을 훈련하는 방법까지 상세히 알아보겠습니다.
목차
LoRA란 무엇인가?
LoRA(Low-Rank Adaptation)는 대규모 AI 모델을 완전히 재훈련하지 않고도 특정 작업이나 스타일에 맞게 세밀하게 조정할 수 있는 기술입니다. 이 방법은 모델의 핵심 가중치를 그대로 유지하면서 저차원 적응층을 추가하여 모델의 동작을 변경합니다.
간단히 말해, LoRA는 모델의 전체를 바꾸지 않고 특정 부분만 조정하여 원하는 효과를 얻는 방법입니다. 이는 마치 자동차 전체를 새로 구매하지 않고 특정 부품만 교체하여 성능을 향상시키는 것과 유사합니다.
Wan 2.1에서 LoRA의 역할
Wan 2.1은 Alibaba Cloud에서 개발한 개방형 AI 비디오 생성 모델로, 텍스트나 이미지를 기반으로 고품질 비디오를 생성합니다. 이 모델에서 LoRA는 다음과 같은 역할을 합니다:
- 스타일 맞춤화: 특정 예술 스타일이나 시각적 효과를 비디오에 적용
- 캐릭터 일관성: 비디오 전체에서 캐릭터의 모습과 동작을 일관되게 유지
- 동작 역학: 특정 동작(예: 회전, 줌인/아웃)을 더 자연스럽게 구현
- 특수 효과: 독특한 시각적 효과나 전환 효과를 추가
이러한 LoRA의 적용은 Wan 2.1의 유연성을 크게 높이고, 일반 사용자도 고급 효과를 쉽게 구현할 수 있게 해줍니다.
기존 LoRA 모델 사용하기
이미 훈련된 LoRA 모델을 사용하는 것은 비교적 간단한 과정입니다. 주로 ComfyUI 환경에서 이루어지며, 아래 단계를 따라 진행할 수 있습니다:

단계별 가이드
- LoRA 모델 다운로드: 원하는 효과나 스타일의 LoRA 모델(.safetensors 파일)을 다운로드합니다. 인기 있는 사이트로는 Civitai, Hugging Face 등이 있습니다.
- 파일 저장: 다운로드한 파일을 ComfyUI의 models/loras/wan 디렉토리에 저장합니다. 디렉토리가 없으면 생성해주세요.
- ComfyUI 로드: ComfyUI를 실행하고 Wan 2.1 모델을 로드합니다.
- LoraLoader 노드 추가: 워크플로우에 LoraLoader 노드를 추가합니다. 노드 메뉴에서 "Add Node > LoRA > LoraLoader"를 선택하면 됩니다.
- 노드 연결: LoraLoader 노드를 메인 모델 노드에 연결합니다. 이때 LoraLoader의 출력을 모델 노드의 입력으로 연결해야 합니다.
- 가중치 설정: LoRA 가중치를 0.8~1.0 사이로 설정합니다. 이 값이 높을수록 LoRA의 효과가 강해집니다.
- 비디오 생성 실행: 워크플로우를 실행하여 LoRA가 적용된 비디오를 생성합니다.
예시 워크플로우 설정
ComfyUI에서 Wan 2.1과 LoRA를 함께 사용하는 기본 워크플로우는 다음과 같습니다:
1. CheckpointLoaderSimple (Wan 2.1 모델 로드)
└─> LoraLoader (LoRA 모델 적용, 가중치: 0.8)
└─> KSampler (샘플링 설정)
└─> VAEDecode (디코딩)
└─> SaveImage (결과 저장)
이러한 방식으로 캐릭터 회전, 줌 효과, 특정 아트 스타일 등 다양한 효과를 간단히 적용할 수 있습니다.
자체 LoRA 모델 훈련하기
원하는 효과나 스타일의 LoRA 모델이 없다면, 직접 훈련시켜 사용할 수 있습니다. 이 과정은 약간의 기술적 지식을 요구하지만, 아래 단계를 따라 진행할 수 있습니다:
단계 세부 내용
| 1. 데이터셋 준비 | 원하는 스타일이나 효과를 반영한 이미지(10~15개) 또는 짧은 비디오(2~3초)를 준비합니다. |
| 2. 데이터셋 구조화 | 각 이미지에 해당하는 설명 텍스트(.txt 파일)를 포함하고, 트리거 단어를 일관되게 사용합니다. |
| 3. 도구 설정 | diffusion-pipe 같은 도구를 설치하고, 훈련 설정을 구성합니다. 예: 에포크 수 100, 학습률 조정. |
| 4. Wan 2.1 모델 다운로드 | Hugging Face에서 Wan 2.1 모델(예: T2V-1.3B)을 다운로드하여 models/WAN2.1_1.3B에 저장합니다. |
| 5. 훈련 실행 | 명령어로 훈련 스크립트를 실행: deepspeed --num_gpus=1 train.py --deepspeed --config examples/wan_video.toml |
| 6. 훈련된 모델 사용 | 훈련된 LoRA 모델(.safetensors)을 ComfyUI의 models/loras에 저장하고, 위와 동일하게 적용합니다. |
데이터셋 준비 상세 가이드
효과적인 LoRA 훈련을 위해서는 고품질 데이터셋이 필수적입니다. 다음과 같이 준비해보세요:
- 이미지 준비: 원하는 스타일이나 효과를 명확히 보여주는 고품질 이미지 10~15개를 선택합니다. 해상도는 512x512 또는 768x768이 권장됩니다.
- 폴더 구조: 아래와 같은 폴더 구조를 만듭니다:
- training_data/ ├── images/ │ ├── image_001.png │ ├── image_002.png │ └── ... └── captions/ ├── image_001.txt ├── image_002.txt └── ...
- 캡션 작성: 각 이미지에 대한 설명 텍스트를 작성합니다. 이때 일관된 트리거 단어(예: "wan_special_effect")를 포함시키는 것이 중요합니다. 예:
- wan_special_effect, a character spinning in a colorful background, 4K quality, smooth motion
훈련 실행 상세 명령어
LoRA 모델 훈련을 위한 전체 명령어는 다음과 같습니다. 필요에 따라 매개변수를 조정할 수 있습니다:
deepspeed --num_gpus=1 train.py --deepspeed --config examples/wan_video.toml \
--dataset_dir training_data \
--output_dir lora_models \
--learning_rate 1e-4 \
--epochs 100 \
--batch_size 1 \
--rank 4 \
--base_model WAN2.1_1.3B
기술적 세부사항
하드웨어 요구사항
Wan 2.1에서 LoRA 사용 시 권장되는 하드웨어:
- LoRA 적용만 할 경우: NVIDIA RTX 3060 이상, 최소 12GB VRAM
- LoRA 훈련 시: NVIDIA RTX 3090/4090 이상, 최소 24GB VRAM 권장
- Image-to-Video 작업에 14B 모델 사용 시: 48GB VRAM 권장
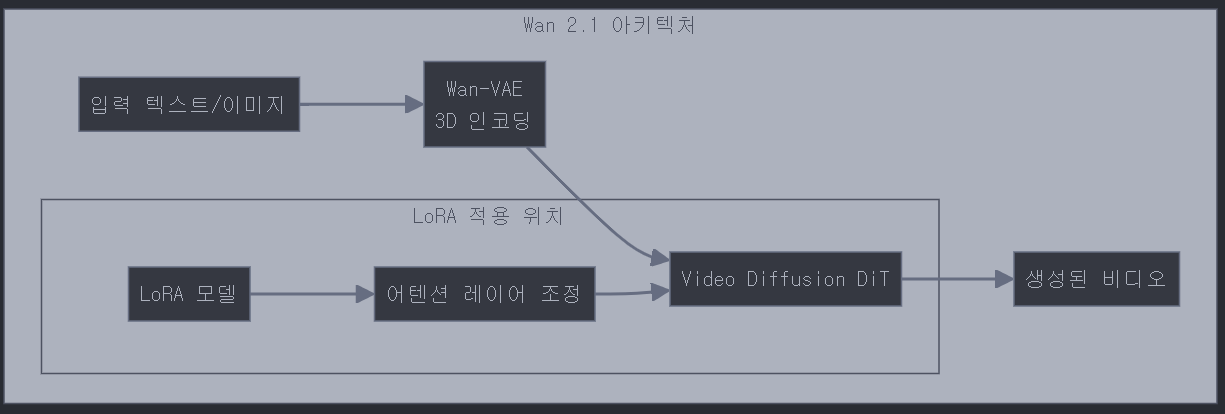
Wan 2.1 아키텍처와 LoRA 적용 위치
Wan 2.1의 아키텍처는 크게 두 부분으로 구성됩니다:
- Wan-VAE: 3D 공간에서 비디오를 인코딩하는 역할
- Video Diffusion DiT: 실제 비디오 생성을 담당하는 부분
LoRA는 주로 DiT 부분의 어텐션 레이어에 적용되지만, 정확한 적용 위치는 공식 문서에서 명확히 밝혀지지 않았습니다. 실제 사용에서는 ComfyUI 워크플로우의 LoRALoader 노드가 이를 알아서 처리합니다.
자주 묻는 질문
Q: LoRA와 일반 파인튜닝의 차이점은 무엇인가요?
A: 일반 파인튜닝은 모델 전체를 재훈련하는 반면, LoRA는 특정 레이어에 저차원 적응층을 추가하여 훨씬 적은 파라미터만 조정합니다. 이로 인해 LoRA는 훈련 시간과 계산 자원이 크게 절약되며, 여러 LoRA를 쉽게 전환할 수 있습니다.
Q: 하나의 모델에 여러 LoRA를 동시에 적용할 수 있나요?
A: 네, ComfyUI에서는 여러 LoraLoader 노드를 연결하여 여러 LoRA를 동시에 적용할 수 있습니다. 단, 효과가 충돌할 수 있으므로 가중치 조정이 필요할 수 있습니다.
Q: LoRA 훈련에 필요한 최소 이미지 수는 몇 개인가요?
A: 최소 5~10개의 이미지로도 기본적인 LoRA를 훈련할 수 있지만, 10~15개의 다양한 이미지를 사용하면 더 좋은 결과를 얻을 수 있습니다.
Q: Wan 2.1 LoRA를 다른 모델(예: Stable Diffusion)에서 사용할 수 있나요?
A: 아니요, Wan 2.1용 LoRA는 Wan 2.1 아키텍처에 맞게 설계되었으므로 다른 모델과 호환되지 않습니다.
결론
Wan 2.1에서 LoRA는 비디오 생성의 유연성과 맞춤성을 크게 높이는 강력한 도구입니다. 기존 모델을 사용하거나 자체 훈련을 통해 원하는 효과를 추가할 수 있으며, ComfyUI를 통해 쉽게 통합할 수 있습니다.
LoRA를 활용하면 전문가 수준의 비디오 효과와 스타일을 일반 사용자도 쉽게 구현할 수 있어, AI 비디오 생성의 무한한 가능성을 탐색할 수 있습니다. 지금 바로 Wan 2.1과 LoRA를 조합하여 여러분만의 독특한 비디오를 만들어보세요!
더 많은 정보와 지원은 다음 리소스에서 찾을 수 있습니다: